
一、问题背景
BIM模型本质上是高度结构化的数据——无论是Revit的.rvt文件还是IFC格式,都包含几何信息、构件属性、空间关系等复杂内容。而大语言模型天生是为“自然语言”设计的,无法直接“阅读”BIM数据。
更关键的是,建筑行业拥有极高的专业壁垒。一个通用LLM可能精通写诗、编程、法律咨询,但面对专业的图纸问题时,往往答非所问。
研究团队通过初步实验总结了通用LLM在BIM设计任务中的四大典型错误:
缺乏推理过程:直接给出答案,没有逐步分析,极易出错;
数学计算能力有限:即使是简单的面积计算,公式正确但结果错误;
误解自然语义:无法理解规则中的括号、连接符等细节;
缺乏领域知识:不知道“层高”与“楼板厚度”的区别,推理逻辑混乱。
除了模型自身能力不足,该领域还存在一个更深层次的问题:既没有评估LLM的基准,也没有高质量的微调数据集。没有基准,就无法量化不同模型的优劣;没有数据,就无法让通用模型“学会”BIM知识。
这正是清华团队要解决的三个核心问题:
1、如何评估LLM在BIM设计任务上的能力?
2、如何构建可用于训练和测试的BIM文本数据集?
3、如何高效微调出适用于BIM设计的领域专用LLM?
二、整体解决方案:基准 + 数据集 + 微调
研究团队提出了一套完整的方法论,如下图所示: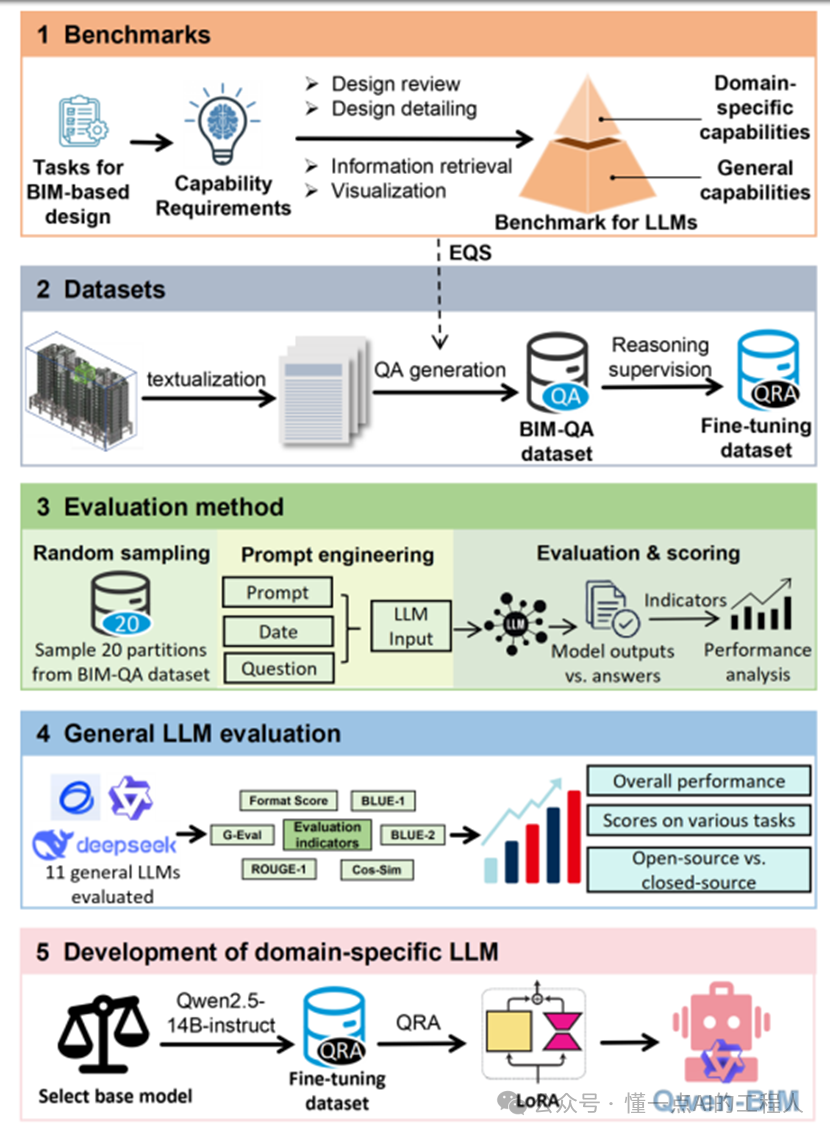
整个流程分为三个阶段:
构建评估基准:首先定义BIM设计任务对LLM的能力需求,然后设计了一套包含22个问题模板的评估问题集(EQS),并引入了包括G-Eval在内的多维度定量指标。
构建领域数据集:提出BIM数据文本化方法,并通过自动注入缺陷,生成了BIM-QA(问答)和BIM-QRA(问题-推理-答案)两类数据集,总计3300个数据对。
微调领域模型:基于评估结果选择Qwen2.5-14B-instruct作为基础模型,采用LoRA参数高效微调,并对比了不同比例推理数据(QRA)对性能的影响,最终得到Qwen-BIM。
三、核心技术拆解
1、BIM数据文本化:让大模型“读懂”构件
BIM数据是结构化的,而LLM需要自然语言输入。研究团队设计了一套半结构化的文本表达方法,将每个构件的信息转化为类似下面的描述:
“第1面墙的ID是342693。其起点坐标为(-1897, -5891, 0),终点坐标为(-1897, -3191, 0)。墙厚200mm,墙高2900mm,墙长2700mm,施工编号为Q23。”
对于复杂的异形板,则通过列出上表面角点坐标来描述其形状。这种表达既保留了结构化数据的准确性,又接近人类工程师的表述习惯,显著降低了LLM的理解难度。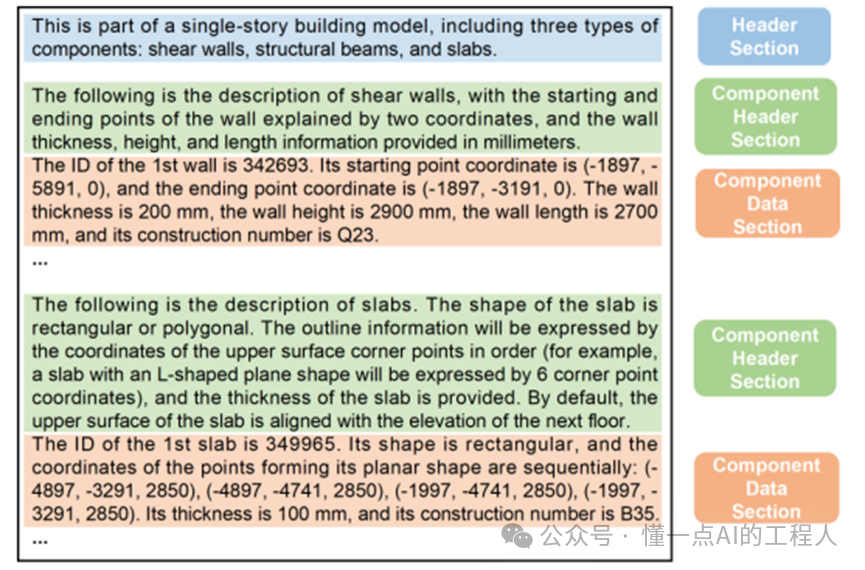
2、评估基准:22个问题模板 + G-Eval打分
评估问题集(EQS)覆盖了通用能力(信息提取、统计、计算、推理)和BIM领域特定能力(完整性检查、合理性检查、合规性检查、设计细化),每个能力又分为不同难度等级。
例如,一个计算能力 Level 3的问题要求模型:
“计算本模型中所有矩形楼板的平面面积(单位:平方米)。请先列出每块楼板的ID、是否为矩形以及面积,最后给出面积最大的楼板ID和面积。”
为了量化评估,团队采用了多指标体系,包括文本相似度指标(BLEU、ROUGE-L)和语义相似度指标(余弦相似度、G-Eval)。其中,G-Eval是使用另一个LLM(GLM-4-plus)按照精细规则打分的,规则明确指出:判断性结果和数据准确性占90%的权重,表达方式差异不扣分,计算误差3%以内算正确。实验证明,G-Eval评分最接近人类专家的判断。
3、数据集构建:从完整BIM模型自动生成缺陷数据
真实工程中,存在缺陷的BIM模型很难大量获取。研究团队采用“先完善、再破坏”的策略:
首先检查并修正BIM模型中的所有错误,得到一个“完美模型”;
然后将模型分割成多个空间区块(每块约10-15个构件),并文本化;
最后根据EQS中的问题类型,随机选择构件并自动注入缺陷:比如擦除施工编号、将墙厚改为20mm(正常应为200mm)、修改防火极限为1小时等。
通过这种方式,团队从商场、办公楼、宿舍、教学楼、博物馆等不同类型的Revit模型中生成了150个区块、共3300个BIM-QA数据对。
在此基础上,他们还构建了BIM-QRA数据——在QA数据中加入了“思维链”式的中间推理步骤。例如,对于合规性检查,QRA数据会先写出“根据规则,结构梁防火极限≥2小时,当前ID为xxx的梁为1.5小时,不满足”,再给出最终答案。实验证明,推理数据是提升模型性能的关键。
4、微调策略:LoRA + QRA比例对比
由于计算资源有限(2张RTX A6000,共96GB显存),研究团队选择了参数高效微调方法LoRA(低秩自适应)。基础模型选用Qwen2.5-14B-instruct,在14B参数规模下能够平衡性能与资源消耗。
为了探索推理数据的作用,他们设置了四组对比实验:
A组:100% QA数据
B组:80% QA + 20% QRA
C组:60% QA + 40% QRA
D组:100% QRA
结果令人意外:数据量最小的D组(仅含QRA)取得了最佳性能,G-Eval评分比基础模型提升了21.0%。这说明在微调过程中,数据质量远比数据数量重要——一个带有清晰推理过程的样本,胜过多个简单的问答对。
四、实验验证:Qwen-BIM的性能有多强?
1、通用LLM评估:推理模型占优,但参数不是越大越好
团队首先评估了11个通用LLM(包括ChatGLM、Qwen、DeepSeek系列)。结果发现:
推理模型(如DeepSeek-R1、QwQ-32B)整体优于非推理模型,因为它们的“思维链”过程有助于理解复杂问题。
但参数规模过大反而可能引入冗余:671B的DeepSeek-R1在格式分上低于32B的QwQ-32B,因为前者输出大量额外信息,偏离了要求的简洁格式。
通用LLM在简单提取和统计任务上表现尚可,但在多步推理、合规性判断、设计细化等BIM领域任务上明显吃力。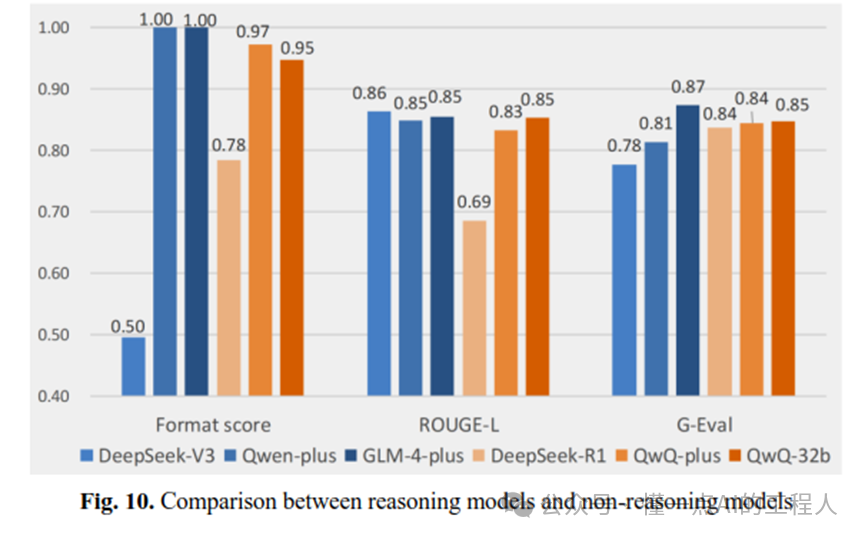
2、Qwen-BIM:14B参数媲美671B模型
微调后的Qwen-BIM与基础模型(Qwen2.5-14B-instruct)相比:
整体G-Eval得分:从0.689提升至0.834(+21.0%)
领域特定任务:从0.588提升至0.801(+36.2%)
格式遵循能力:从84.7%提升至90.2%
更令人印象深刻的是,Qwen-BIM(14B)的G-Eval得分(0.834)几乎追平了DeepSeek-R1(671B)的0.84。这意味着,通过精心设计的领域微调,一个小体量模型完全可以替代超大通用模型完成BIM设计任务,大大降低了部署成本。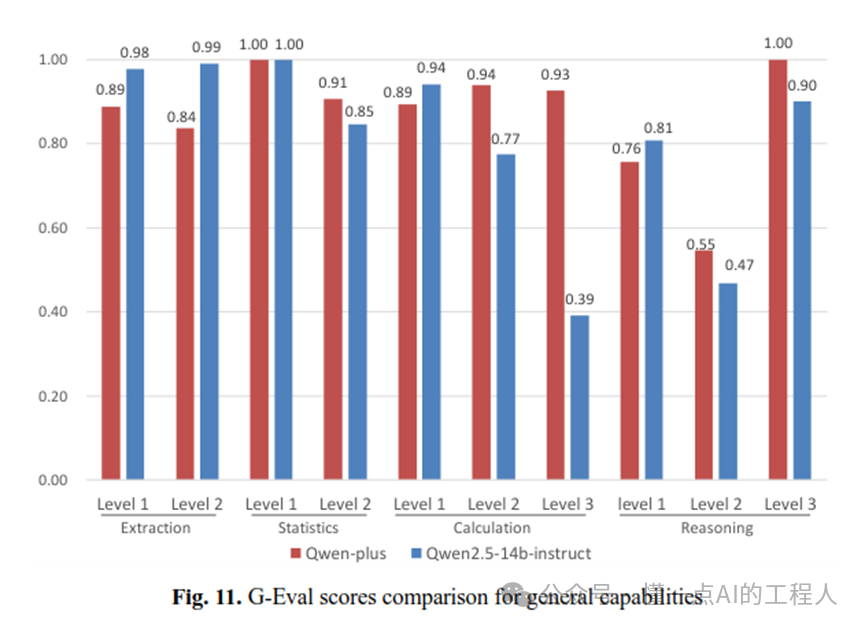
3、哪些任务提升最大?
从细粒度分析来看,Qwen-BIM在以下类型的题目上提升最显著:
合理性检查(如判断墙厚是否在合理范围内):提升超过0.3分
合规性检查(如判断防火极限是否满足规范):提升约0.25分
设计细化(如为非合规构件给出修正值):提升约0.2分
而在简单的数据提取和统计任务上,提升幅度较小(约0.05~0.1),因为这些任务基础模型已经做得不错,改进空间有限。
五、技术特点与适用场景
1、首个BIM设计领域的专用LLM评估体系
此前,建筑行业缺乏统一的LLM评估标准。该研究提出的EQS+多指标体系,可迁移到其他BIM相关任务(如施工模拟、运维管理)中,为后续研究提供了可复用的框架。
2、数据驱动,不依赖预设规则
与传统的基于规则的设计审查系统不同,Qwen-BIM通过微调学习到了设计常识和规范知识,能够处理非结构化、语义多样的问题。例如,当被问到“这面墙的厚度是否可疑”时,模型可以结合“一般住宅墙厚范围”进行推理,而不是硬编码一个阈值。
3、轻量化部署成为可能
Qwen-BIM只有14B参数,可以在消费级GPU(如24GB显存)上运行,大幅降低了BIM设计智能化的硬件门槛。对于设计院、施工企业而言,这意味着不需要采购昂贵的服务器即可部署AI辅助设计工具。
4、支持设计-审查-细化闭环
该模型不仅能发现问题,还能提出修改建议,初步形成了“识别缺陷→推荐修正”的辅助设计能力。
六、未来展望
尽管Qwen-BIM在BIM设计任务上取得了突破,但研究团队指出,目前的工作仍有多个值得深化的方向:
1、从2D推理走向3D空间计算
当前的EQS有意避开了3D碰撞检测等复杂空间计算问题,因为通用LLM在这方面的能力非常薄弱。未来可以通过几何编码器+LLM的多模态架构,让模型直接理解构件的三维空间关系。
2、融入更多规范与工程知识
目前的合规性检查仅覆盖了施工编号、防火极限等少数规则。实际工程中涉及上百本规范、数万条条款。未来的工作可以将规范文本结构化后融入微调数据,构建更全面的合规检查能力。
3、从文本输出到BIM模型直接修改
当前Qwen-BIM的输出是自然语言文本(如“建议将墙厚改为200mm”)。下一步可以开发BIM模型编辑工具,让LLM直接通过API修改Revit或IFC文件中的参数,实现真正的“对话式设计”。
4、跨项目知识迁移
一个在大量BIM模型上微调过的LLM,是否能够将知识迁移到新的、未见过的建筑类型?这是一个值得探索的领域自适应问题。
七、结语
清华大学这项研究的核心价值,并不仅仅在于他们微调出了一个性能优异的Qwen-BIM模型,而在于他们系统性地填补了BIM领域LLM评估与数据的基础空白。
在此之前,建筑行业的研究者想要尝试LLM,要么直接调用ChatGPT API,要么简单收集一些问答对进行微调——缺乏统一的度量衡,结果难以复现,也难以横向比较。而该研究提供的评估基准、量化指标、数据集构建方法、微调策略,为后续所有BIM+LLM的研究奠定了基石。